
AI chatbots in everyday business life: How to maintain control over your data

Philipp
December 3, 2025
Imagine the following scenario: You receive a phone call. "We discovered that our intern entered sensitive architectural documentation into his personal ChatGPT account. What can we do?" The answer is painful: "It's probably too late." Even worse: Most of the time, you don't even get the call. However, you can prevent this from happening in the future.
The problem: Shadow AI is consuming your company's data
According to a Bitkom article from October 21, 2025, four out of ten companies assume that their employees use private AI tools, referred to here as shadow AI. However, only 26% of companies provide official access.
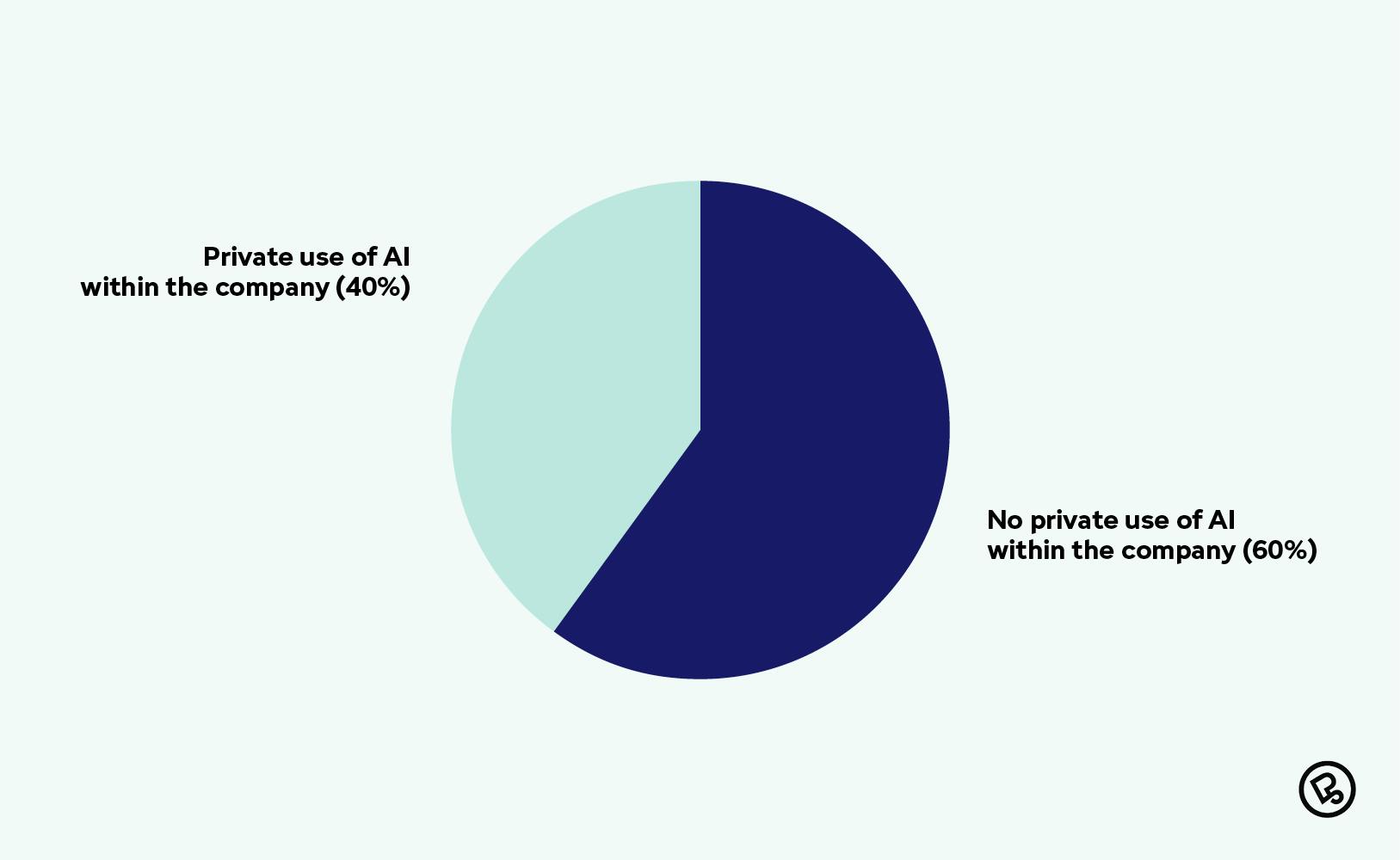
Private use of AI in German companies
This means that in nearly half of German companies, AI use is uncontrolled. Your employees use ChatGPT, Claude, or Gemini with their personal accounts anyway. They copy product specifications, internal code snippets, customer data, and development roadmaps. Why? Because it makes their work much easier, and no one has offered them an alternative.
The problem is that some of this data ends up at OpenAI, Anthropic, or Google. Currently, your data may not be included in the AI's knowledge base, as the models have a knowledge cutoff. For example, GPT5 only has knowledge up to October 2024. However, it may be included in the next model update. Thus, your internal knowledge is becoming public knowledge.
Shadow AI is a symptom, not the problem itself. The real problem is that your employees have a legitimate need for AI support but no secure way to use it. You could try to block private AI tools. Or provide enterprise chatbots like MS Copilot. Or you could go one step further: build an AI solution that is better than the private tools. One that is not only secure, but also has access to your internal data. That's where RAG comes in.
The solution: A chatbot that knows your data and keeps it
Imagine:
- Your product manager asks, "What features are planned for Q1 of 2026, and what customer feedback do we have on them?"
- Your developer asks, "How did we solve the OAuth integration in the legacy system?"
- Your sales team asks, "Show us all the projects we've done for automotive suppliers, including the tech stack."
- Your project manager asks, "Show me all the available, relevant information on the status of Project 123 from the available sources (e.g., GitHub, time tracking, ERP). Summarize it for me and derive the next steps."
The chatbot responds with relevant information from your Confluence pages, Jira tickets, Git repositories, and internal wikis. However: The data never leaves your infrastructure; the magic word is RAG (Retrieval-Augmented Generation).
How RAG works
RAG is like a team of experts:
- The archivist searches your company's data in real time to find relevant information.
- The analyst prepares this information.
- The Eloquent Advisor formulates a comprehensible answer based on this information.
LLM is used in various phases of this team of experts. For example, it is used by both the analyst and the advisor. In this example, a recipe database is part of the RAG system. The system prompt establishes the general context, and the user searches for "Kasspatzn," for instance. The search function revises the input and outputs context-related content from the recipe database.
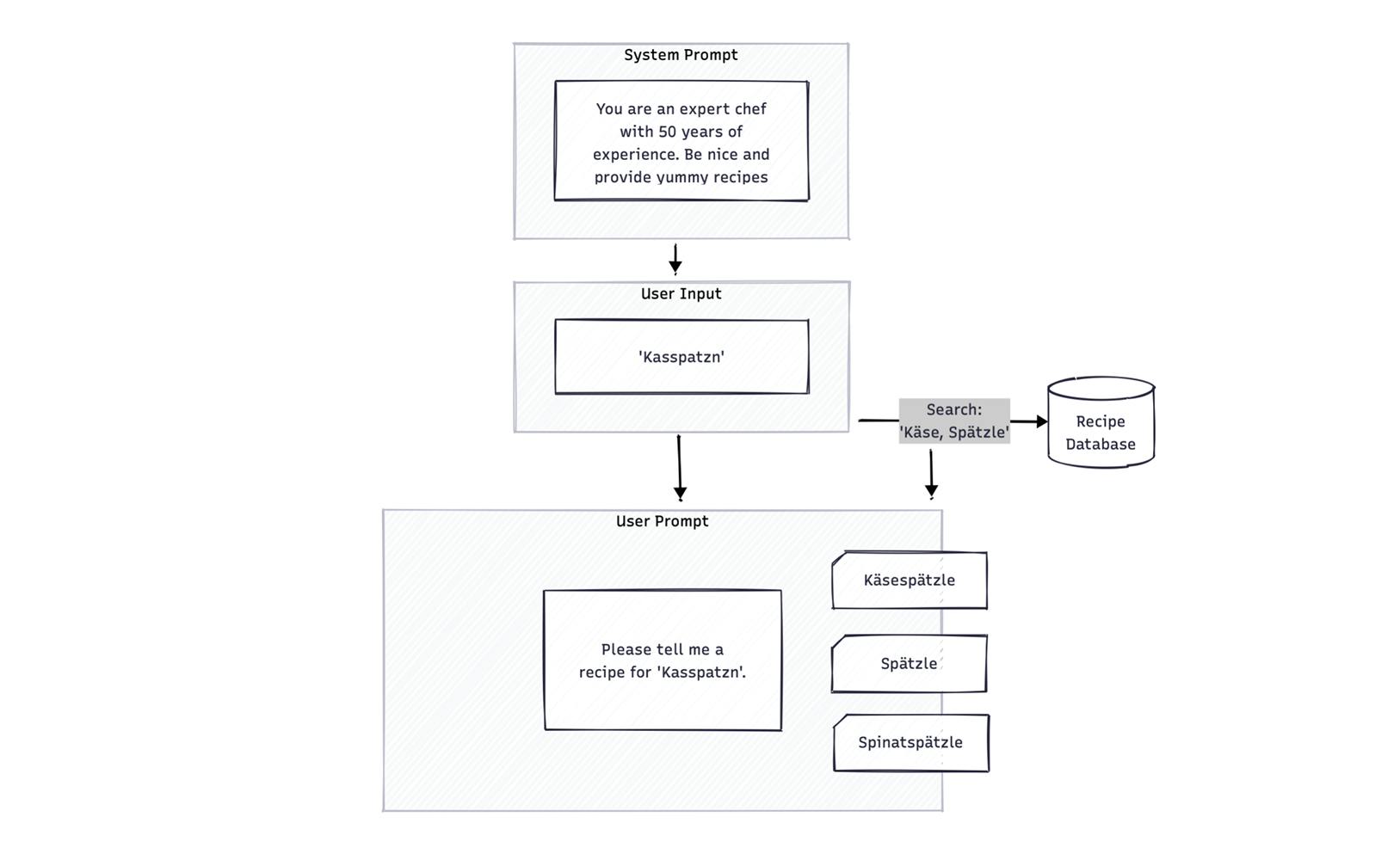
RAG system
The beauty of it is that: An LLM doesn't "invent" anything. It only works with your actual data. This data remains yours, whether it's stored on your own server or in a GDPR-compliant cloud environment in the EU.
What this means specifically
Scenario 1 Onboarding: The new colleague starts on Monday. Rather than spending three weeks combing through the wiki, she asks, "What is our deployment process for microservices?" She receives an answer with links to the relevant documents in 10 seconds.
Scenario 2 Product Launch: Marketing is planning a product launch. The chatbot pulls the current feature status from Jira, the technical specifications from Confluence, and the previous launch learnings from retrospectives. A comprehensive overview is provided in minutes instead of days.
Scenario 3 Technical Debt: The CTO asks, "Which components still use the old authentication library?" The bot searches ad hoc code repositories, issues, and architecture documentation. Prioritization can begin immediately.
Role-based access: Not everyone sees everything
Of course, not everyone needs access to everything. Your RAG system can operate on a role-based basis.
- Developers can see code repositories, technical documents, and Jira.
- Product management sees roadmaps, customer feedback, and analytics.
- Sales sees reference projects, case studies, and product features.
- Management can see everything (or only high-level reports, depending on the requirements).
By integrating tool calls (through MCP) based on your employees' access data, you can ensure that only authorized users can access the information. This way, information remains in the respective areas as needed.
Cloud or on-premises? Both are possible, and there are many options in between.
Ultimately, you have more options than just open-source models on your own hardware or proprietary models directly from providers such as OpenAI. In reality, there are many variations in between. For example, you can use open-source models in the cloud or proprietary models via cloud providers in Europe. This allows you to benefit from existing data protection agreements with AWS, for example.
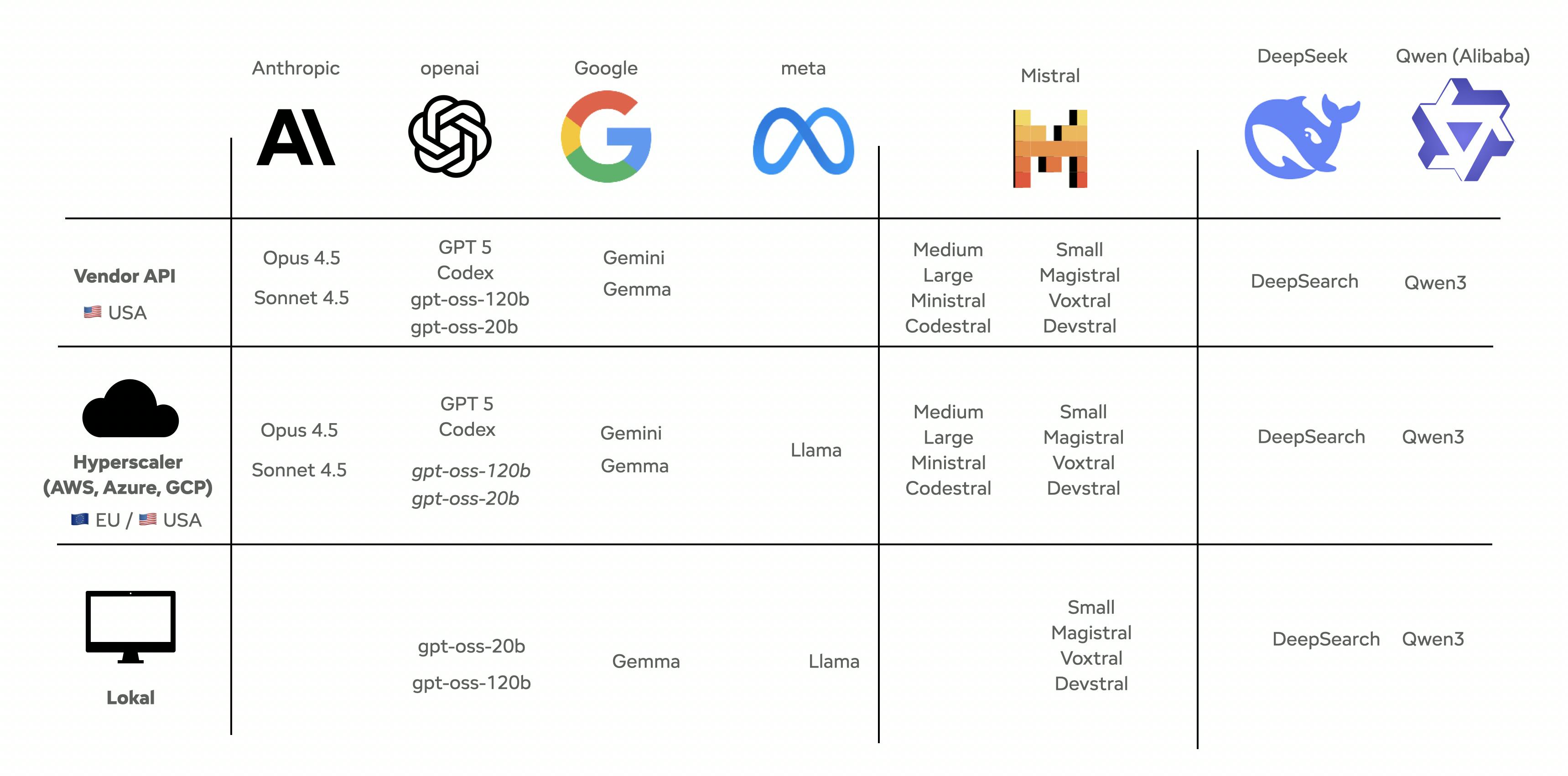
Overview of cloudprovider in Europe
Simple Option 1: Within the EU Cloud (GDPR Compliant) Models from OpenAI, Claude, and Mistral run on AWS, Azure, and GCP in various EU regions (e.g., Belgium). A hosting contract that includes clear data protection clauses ensures that data remains in the EU.
If sustainability is important to you, note that data centers in Stockholm or Norway have electricity that is three times cleaner than that in Frankfurt. My colleague Michael has already described this very nicely here.
Simple option 2: On-premises models, such as Llama, Magistral, and German alternatives, such as Aleph Alpha, run entirely on your own hardware.
How much does something like that cost?
As is often the case, it depends. Here is a rough estimate:
A prototype (3-4 weeks):
- RAG system with one data source containing structured data (e.g., Confluence).
- Basic UI for testing
- Starting at approx. 25.000 EUR.*
A productive system (2-3 months):
- Multiple data sources (Confluence, Jira, Git, SharePoint, etc.).
- Role-based access
- Integration with existing tools (Slack, Teams, etc.)
- Unlimited users
- Approximately 50.000 - 120.000 EUR *
* Of course, an exact estimate depends on your requirements, but we would be happy to discuss them with you.
Does that sound like a lot? Let's estimate how much time your employees spend searching for information each day. With 30 employees each saving 30 minutes per day, that's 315 hours per month. At an internal hourly rate of 80 EUR, that's 25,200 EUR in productivity gains per month. Even with a larger setup, that's an ROI in about five months.
Conclusion: Act pragmatically based on experience.
Our previous projects demonstrate that RAG systems can be implemented gradually in a corporate setting. It is important to start small with a specific use case, real data sources, and clear goals. This enables you to identify early on where the greatest benefits lie and what requirements arise for further expansion. It is important to strike a balance between technical feasibility, data protection, and team acceptance. After all, an AI system is only as valuable as its everyday use. With this approach, you can control your data and lay the groundwork for more efficient work and accessible knowledge.
Header picture by Maisey Dillon on Unsplash

Unsure whether RAG is the right approach?
Let's discuss your specific use case to find a concrete solution. Together, we'll review the benefits, data situation, and risks. This will save you time, help you determine your next steps, and allow you to maintain control of your data.
AI Chatbots
Generative AI
Enterprise AI
Retrieval-Augmented Generation (RAG)
Read also

Irena, 03/11/2026
Robotics in Balance: How digital solutions make physical processes smarter
Industry 4.0
Digital process optimization
Data visualization
Modular robotics solutions
Automation
Predictive maintenance
Smart Factory Software

Philipp, 03/11/2026
From Excel chaos to competitive advantage: established processes as the perfect foundation for B2B portals
Digital Transformation
Process Automation
Data Management
Custom Software Development
Business Process Digitization

Niklas, 03/09/2026
Are Passkeys Ready for Prime Time? – The Security Perspective (Part 1)
Passkeys
Passwords
Passwordless Authentication
Public-Key Cryptography
Challenge-Response Authentication