
KI-Chatbots im Unternehmensalltag: Wie du die Kontrolle über deine Daten behältst

Philipp
3. Dezember 2025
Stelle dir bitte einmal folgendes Szenario vor: Ein Anruf: "Wir haben entdeckt, dass unser Praktikant sensible Architektur-Dokumentation in seinem privaten ChatGPT eingegeben hat. Was können wir tun?" Die Antwort tut weh: Es ist wahrscheinlich zu spät. Noch schlimmer: Meistens kommt der Anruf überhaupt nicht bei dir an. Aber für die Zukunft kannst du vermeiden, dass es dazu kommt.
Das Problem: Die Schatten-KI frisst deine Firmendaten
Laut dem Bitkom-Artikel vom 21. Oktober 2025 gehen 4 von 10 Unternehmen davon aus, dass ihre Mitarbeitenden private KI-Tools nutzen (hier Schatten-KI genannt). Gleichzeitig stellen nur 26% der Unternehmen einen offiziellen Zugang bereit.
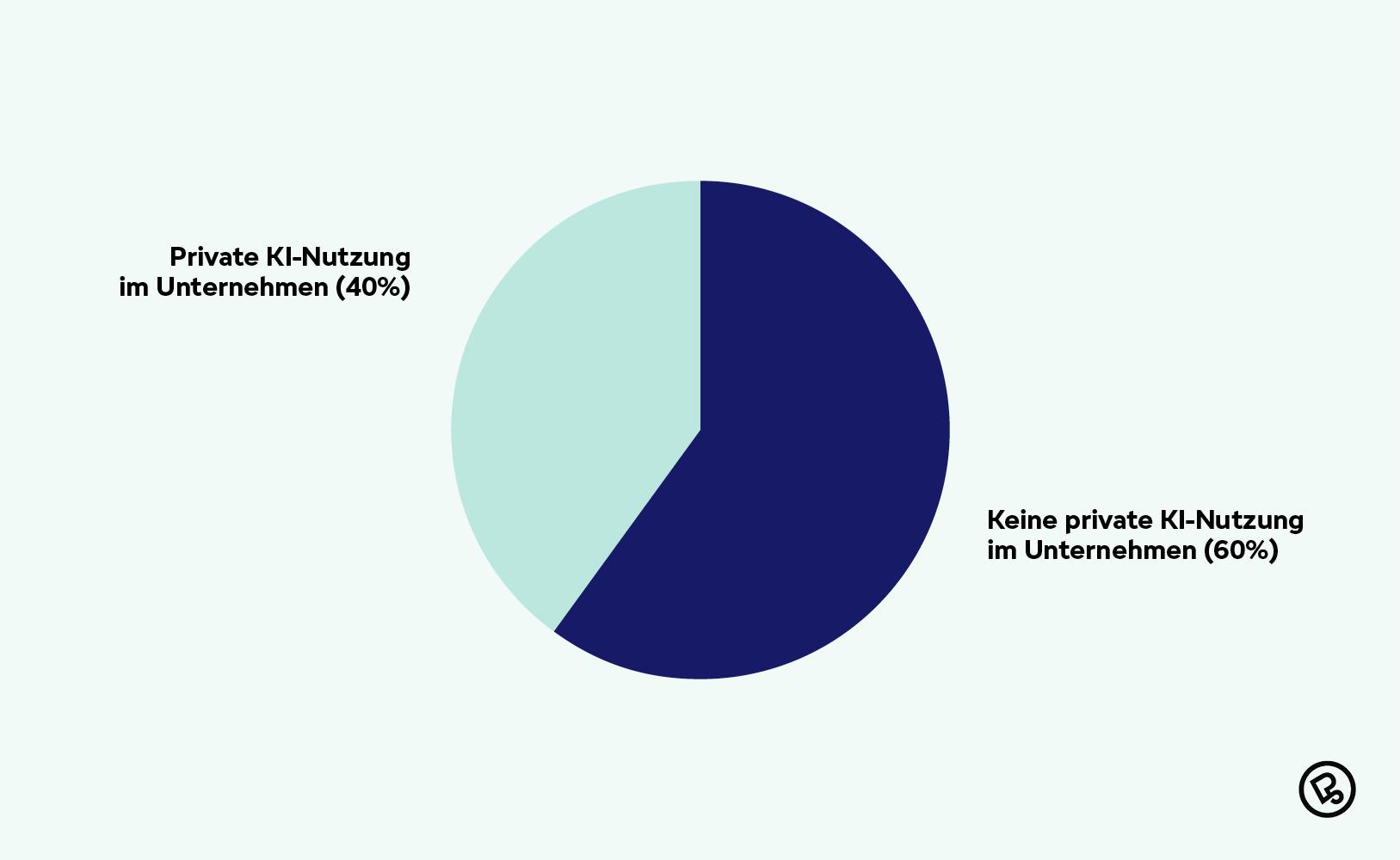
Private KI-Nutzung in deutschen Unternehmen
Das bedeutet: In fast jedem zweiten deutschen Unternehmen läuft KI-Nutzung unkontrolliert. Deine Leute nutzen ChatGPT, Claude oder Gemini sowieso, aber mit ihren privaten Accounts. Sie kopieren Produktspezifikationen rein, interne Code-Snippets, Kundendaten, Entwicklungs-Roadmaps. Warum? Weil es ihre Arbeit massiv erleichtert und niemand ihnen eine Alternative bietet.
Das Problem: Diese Daten landen (teilweise) bei OpenAI, Anthropic oder Google. Heute findest du deine Daten vielleicht noch nicht im Wissen der KIs (Hier gibt es bei den Modellen den sogenannten Knowledge Cutoff. Das heißt, dass GPT5 beispielsweise nur Wissen bis zum Oktober 2024 hat), aber beim nächsten Modell-Update möglicherweise schon. Dein internes Wissen wird also gerade zu öffentlichem Wissen.
Schatten-KI ist ein Symptom, nicht das Problem selbst. Das eigentliche Problem ist: Deine Mitarbeitenden haben ein legitimes Bedürfnis nach KI-Unterstützung, aber keine sichere Möglichkeit, sie zu nutzen. Du könntest jetzt versuchen, private KI-Tools zu blockieren. Oder Enterprise Chatbots wie MS Copilot zur Verfügung stellen. Oder du gehst einen Schritt weiter: Du baust eine KI-Lösung, die besser ist als die privaten Tools. Eine, die nicht nur sicher ist, sondern auch Zugriff auf eure internen Daten hat. Das ist der Punkt, wo RAG ins Spiel kommt.
Die Lösung: Ein Chatbot, der deine Daten kennt und für sich behält
Stell dir vor:
- Deine Produktmanagerin fragt: „Welche Features sind für Q1 2026 geplant und welche Kundenfeedbacks haben wir dazu?"
- Dein Entwickler fragt: „Wie haben wir die OAuth-Integration im Legacy-System gelöst?"
- Dein Sales-Team fragt: „Zeige mir alle Projekte, die wir für Automobilzulieferer gemacht haben, inklusive Tech-Stack"
- Dein Projektmanager fragt: Zeige mir alle verfügbaren, relevanten Informationen zu Status von Projekt „123“ aus den verfügbaren Quellen (bspw. Github, Time-Tracking, ERP), fasse sie mir zusammen und leite die nächsten Schritte ab.
Der Chatbot antwortet mit Kontext aus euren Confluence-Seiten, Jira-Tickets, Git-Repositories, internen Wikis. Aber: Die Daten verlassen nie eure Infrastruktur. Das Zauberwort heißt RAG (Retrieval-Augmented Generation).
Wie RAG im Prinzip funktioniert
RAG ist wie ein Experten-Team:
- Der Archivar durchsucht eure Unternehmensdaten und findet relevante Informationen
- Der Analyst bereitet diese Informationen auf
- Der eloquente Berater formuliert daraus eine verständliche Antwort
In diesem Expertenteam wird das LLM in verschiedenen Phasen eingesetzt. Beispielsweise als Analyst und Berater. In der beispielhaften Darstellung ist eine Rezeptdatenbank Teil des RAG Systems. Der System Prompt setzt den generellen Kontext und die Nutzerin sucht mit Ihrer Eingabe beispielsweise nach „Kasspatzn“. Eine Suchfunktion überarbeitet diese Eingabe entsprechend und kontextbezogene Inhalte werden aus der Rezeptdatenbank herausgegeben.
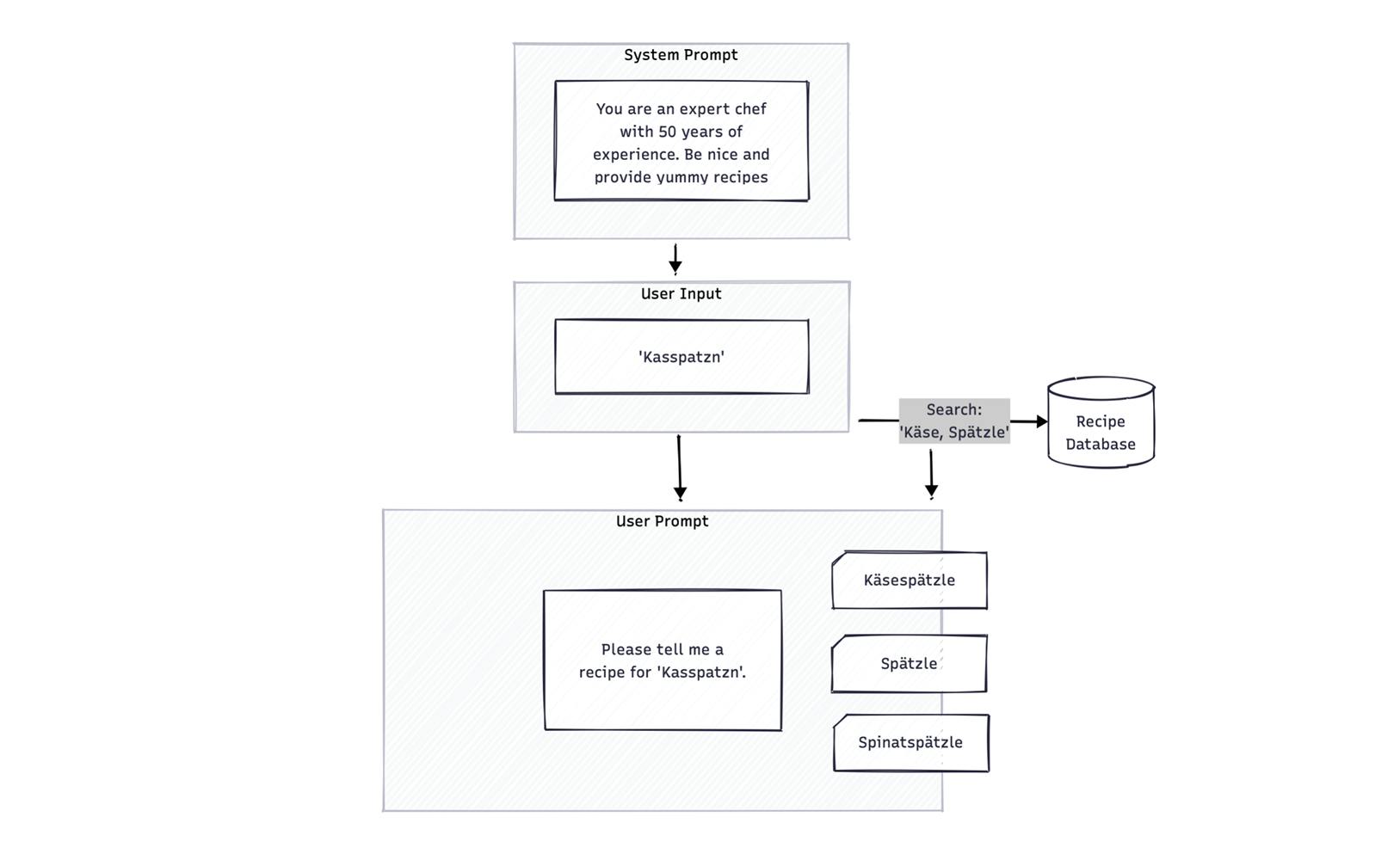
RAG-System
Der Schöne: Das LLM "erfindet" nichts. Es arbeitet nur mit euren echten Daten. Und diese Daten bleiben bei euch. Ob auf eurem eigenen Server oder in einer GDPR-konformen Cloud-Umgebung in der EU.
Was das konkret bedeutet
Szenario 1 Onboarding: Die neue Kollegin startet am Montag. Statt drei Wochen Wiki-Durchforsten fragt sie: "Wie ist unser Deployment-Prozess für Microservices?" Die Antwort kommt in 10 Sekunden, mit Links zu den relevanten Dokumenten.
Szenario 2 Produktlaunch: Das Marketing plant einen Produktlaunch. Der Chatbot zieht sich aktuelle Feature-Status aus Jira, technische Spezifikationen aus Confluence und bisherige Launch-Learnings aus Retrospektiven zusammen. Ein umfassender Überblick in Minuten statt Tagen.
Szenario 3 Technical Debt: Der CTO fragt: "Welche Komponenten nutzen noch die alte Authentication-Library?" Der Bot durchsucht ad-hoc Code-Repos, Issues und Architektur-Dokumentation. Priorisierung kann sofort beginnen.
Rollenbasierter Zugriff: Nicht jeder sieht alles
Natürlich muss nicht jeder Zugriff auf alles haben. Dein RAG-System kann rollenbasiert arbeiten:
- Entwickler sehen Code-Repos, technische Docs, Jira
- Produktmanagement sieht Roadmaps, Customer Feedback, Analytics
- Sales sieht Referenzprojekte, Case Studies, Produkt-Features
- Geschäftsführung sieht alles (oder nur High-Level-Reports, je nach Bedarf)
Durch die Integration von Tool Calls (durch MCP) auf Basis der Zugangsdaten eurer Mitarbeitenden kann ebenso sichergestellt werden, dass nur gesehen werden kann, worauf die jeweiligen Mitarbeitenden sowieso Zugriff haben. So bleiben Informationen bei Bedarf in den jeweiligen Bereichen.
Cloud oder On-Premise? Beides geht - und vieles dazwischen
Im Endeffekt hast du nicht nur die Option zwischen Open Source Modellen auf deiner eigenen Hardware und proprietären Modellen direkt über Provider wie OpenAI. In Wahrheit gibt es viele Variationen dazwischen. Genauso gut kannst du Open Source Modelle in der Cloud oder auch proprietäre Modelle über Cloudprovider in Europa nutzen. Hier hast du dann den Vorteil, dass du von bestehenden Datenschutzvereinbarungen mit beispielsweise AWS profitieren kannst.
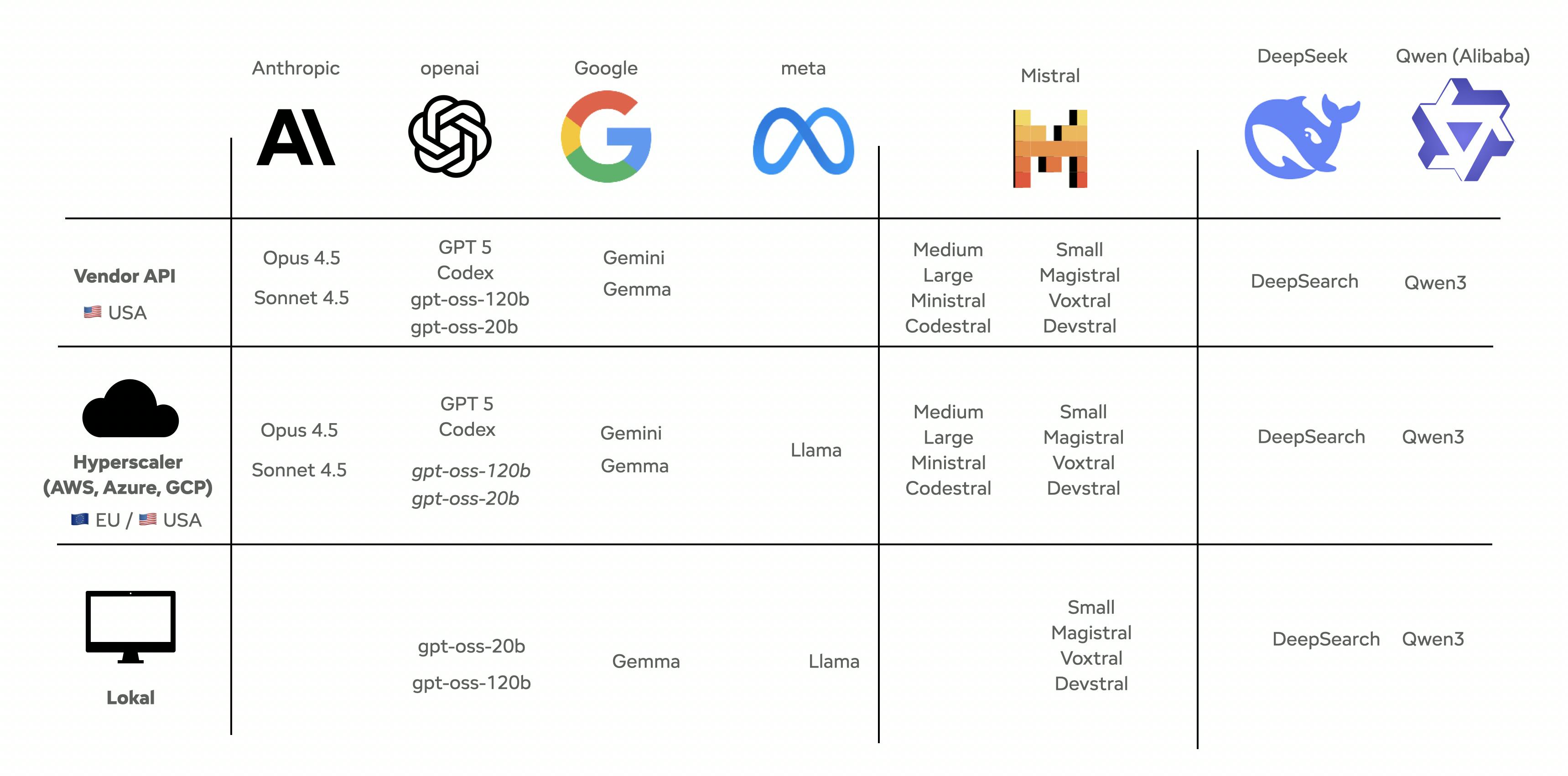
Übersicht Cloudprovider in Europa
Einfache Option 1: Innerhalb der EU-Cloud (GDPR-konform) Modelle von OpenAI, Claude oder Mistral laufen über AWS, Azure oder GCP in verschiedensten Regionen innerhalb der EU. (Belgien). Daten bleiben in der EU mit einem Hosting-Vertrag mit klaren Datenschutz-Klauseln.
Bonus: Wenn dir Nachhaltigkeit wichtig ist --> Rechenzentren in Stockholm oder Norwegen haben 3x saubereren Strom als Frankfurt. Das hat mein Kollege Michael hier bereits sehr schön beschrieben.
Einfache Option 2: On-Premise Modelle wie Llama, Magistral oder deutsche Alternativen wie Aleph Alpha laufen komplett auf eurer eigenen Hardware.
Was kostet so etwas?
Das kommt, wie so oft, drauf an. Aber hier einmal eine grobe Schätzung:
Ein Prototyp (3-4 Wochen):
- RAG-System mit einer Datenquelle mit strukturierten Daten (z.B. Confluence)
- Basis-UI zum Testen
- Start ab ca. 25.000 EUR*
Ein produktives System (2-3 Monate):
- Mehrere Datenquellen (Confluence, Jira, Git, SharePoint, etc.)
- Rollenbasierte Zugriffe
- Integration in bestehende Tools (Slack, Teams)
- Unbegrenzte User
- ca. 50.000 - 120.000 EUR*
* Eine genaue Schätzung hängt natürlich von euren Wünschen ab. Das können wir aber gerne in einem Gespräch erarbeiten.
Klingt das nach viel? Dann lass uns mal überschlagen, wie viel Zeit deine Mitarbeitenden täglich mit Informationssuche verbringen. Bei 30 Mitarbeitenden, die jeweils 30 Minuten pro Tag sparen, sind das 315 Stunden/Monat. Bei einem internen Stundensatz von 80 EUR = 25.200 EUR/Monat an Produktivitätsgewinn. Das ist selbst bei einem größeren Aufbau ein ROI in ca. 5 Monaten.
Fazit: Aus Erfahrung pragmatisch handeln
Unsere bisherigen Projekte zeigen, dass sich der Aufbau von RAG-Systemen im Unternehmenskontext gut schrittweise umsetzen lässt. Entscheidend ist, klein anzufangen. Mit einem konkreten Anwendungsfall, realen Datenquellen und klaren Zielen. So lässt sich früh erkennen, wo der größte Nutzen entsteht und welche Anforderungen sich daraus für den weiteren Ausbau ergeben. Wichtig ist dabei immer die Balance zwischen technischer Machbarkeit, Datenschutz und Akzeptanz im Team. Denn ein KI-System ist nur so wertvoll, wie es im Alltag genutzt wird. Mit einem solchen Ansatz behältst du die Kontrolle über eure Daten - und schaffst gleichzeitig die Grundlage für effizienteres Arbeiten und besser zugängliches Wissen.
Titelfoto von Maisey Dillon auf Unsplash

Unsicher, ob RAG der richtige Ansatz ist?
Lass uns über euren konkreten Anwendungsfall sprechen und schauen, ob wir eine konkrete Lösung dafür finden können. Wir schauen uns dazu gemeinsam Nutzen, Datenlage und Risiken an. So sparst du Zeit, fokussierst die nächsten Schritte an und behältst die Kontrolle über deine Daten.
KI-Chatbots
Generative KI
AI im Unternehmen
RAG (Retrieval-Augmented Generation)
Weitere Themen

Irena, 11.03.2026
Robotik im Gleichgewicht: Wie digitale Lösungen physische Prozesse intelligenter machen
Industrie 4.0
Digitale Prozessoptimierung
Datenvisualisierung
Modulare Robotik-Lösungen
Automatisierung
Predictive Maintenance Robotik
Smart Factory Software

Philipp, 11.03.2026
Vom Excel Chaos zum Wettbewerbsvorteil: Etablierte Prozesse als perfektes Fundament für B2B-Portale
Digitale Transformation
Prozessautomatisierung
Datenmanagement
Individuelle Softwareentwicklung
Geschäftsprozesse digitalisieren

Niklas, 09.03.2026
Sind Passkeys bereit für den breiten Einsatz? – Die Sicherheitsperspektive (Teil 1)
Passkeys
Passwords
Passwordless Authentication
Public-Key Cryptography
Challenge-Response Authentication